Gemini Embedding 2
Released 3mo ago
Multimodal
|ML
|Research
|Operations

blog.google
blog.google
The Vision: Why Gemini Embedding 2 Exists
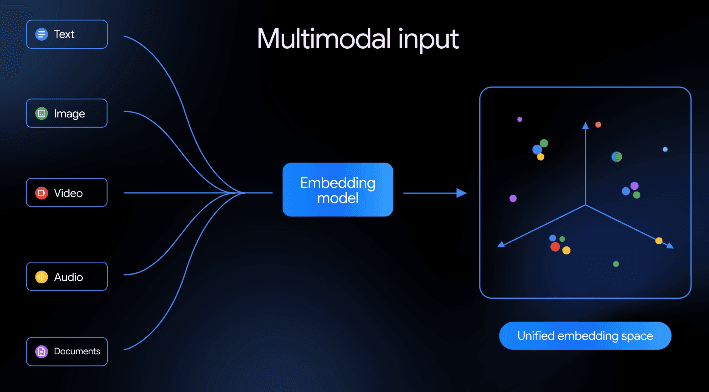
Gemini Embedding 2 is the universal semantic translator for heterogeneous data types. It solves the core bottleneck of "siloed embeddings," where text, images, and audio traditionally required separate models that could not communicate in the same mathematical space. By mapping all modalities into a single vector space, it enables seamless cross-modal understanding. Here are specific personas who benefit most:
- RAG Engineers: Developers building Retrieval-Augmented Generation systems that need to pull context from videos, PDFs, and audio files simultaneously.
- Search Architects: Professionals designing enterprise search engines that allow users to find specific video moments using natural language queries.
- Data Scientists: Researchers working on complex datasets where the relationship between visual and textual information is critical for classification or clustering.
The Engine: How the "Secret Sauce" Works
AI Technology: Multimodal.
Input-Output Loop: User provides text, images, audio, or video files vs AI generates a high-dimensional numerical vector (embedding) representing the semantic meaning.
Innovation highlights:
- Native Multimodality: Unlike "late-fusion" models that stitch different models together, this model is trained from the ground up to understand multiple modalities in one pass.
- Unified Vector Space: Text and images are converted into vectors that are directly comparable, allowing for "text-to-image" or "image-to-audio" similarity math.
- Document Understanding: Enhanced capability to embed complex documents where layout, text, and imagery are all essential to the meaning.
The Toolkit: Capabilities & Connectivity
Flagship Features:
- Cross-Modal Retrieval: Search through a massive library of videos or images using only a text prompt with high precision.
- Optimized RAG Performance: Provides more accurate context for LLMs by including non-textual data in the retrieval step.
Integrations: Google Cloud Vertex AI, Google AI Studio, and Pinecone/Weaviate vector databases.
The Proof: Market Trust
Status: Backed by Google DeepMind.
- State-of-the-Art Benchmarks: Outperforms previous unimodal models in cross-modal retrieval tasks.
- Global Infrastructure: Deployed via Google Cloud, ensuring enterprise-grade scalability and low latency.
- Gemini Ecosystem: Integrated as the foundational embedding layer for the broader Gemini 2.0 model suite.
The Full Picture: Value & Realism
| Pros | Cons |
|---|---|
| Eliminates the need for multiple specialized embedding models. | Higher computational cost compared to simple text-only embeddings. |
| Enables sophisticated search across video and audio archives. | Requires specialized vector databases to handle high-dimensional multimodal data. |
Pricing
- Free Tier: Available for testing and prototyping via Google AI Studio with rate limits.
- Pay-as-you-go: Usage-based pricing via Vertex AI based on the number of characters or media units processed.
- Enterprise: Custom pricing for high-volume production environments with dedicated support.
Frequently Asked Questions
Q1: Does this model require separate encoders for images and text?
A: No, it is natively multimodal, meaning a single model architecture handles all supported data types within the same space.
Q2: Can I use this for real-time video search?
A: Yes, by embedding video frames or segments, you can perform near-instantaneous semantic searches across video libraries.
Q3: What vector dimensions does it support?
A: It typically supports flexible output dimensions, allowing developers to balance retrieval accuracy with storage costs.